
Cough and Crowd Detector for COVID-19 Monitoring
Clara Fontaine (cyf3) & Chloe Wu (jw995)
ECE 5725 Embedded OS Final Project
December 19th, 2020
Clara Fontaine (cyf3) & Chloe Wu (jw995)
ECE 5725 Embedded OS Final Project
December 19th, 2020
Cough and crowd detector for COVID -19 Monitoring is an embedded system that tracks the number of people and number of coughs in the room. This project is inspired by the current pandemic situation and FluSense. FluSense is a device developed by researchers in UMass Amherst that uses cough data and predicts trends in infectious respiratory illnesses, such as influenza. We believe that a system that is able to detect coughing and track the number of people in public places will be useful for COVID forecasting and tracking. We envision this system being used in hospital waiting rooms, common gathering spaces in dorms and school/university buildings, etc.






To detect the number of coughs in the room, we needed to build a machine learning model that can distinguish coughs from various background noises. We found Edge Impulse, which was an online platform to build embedded machine learning models that can be deployed on different microcontrollers.
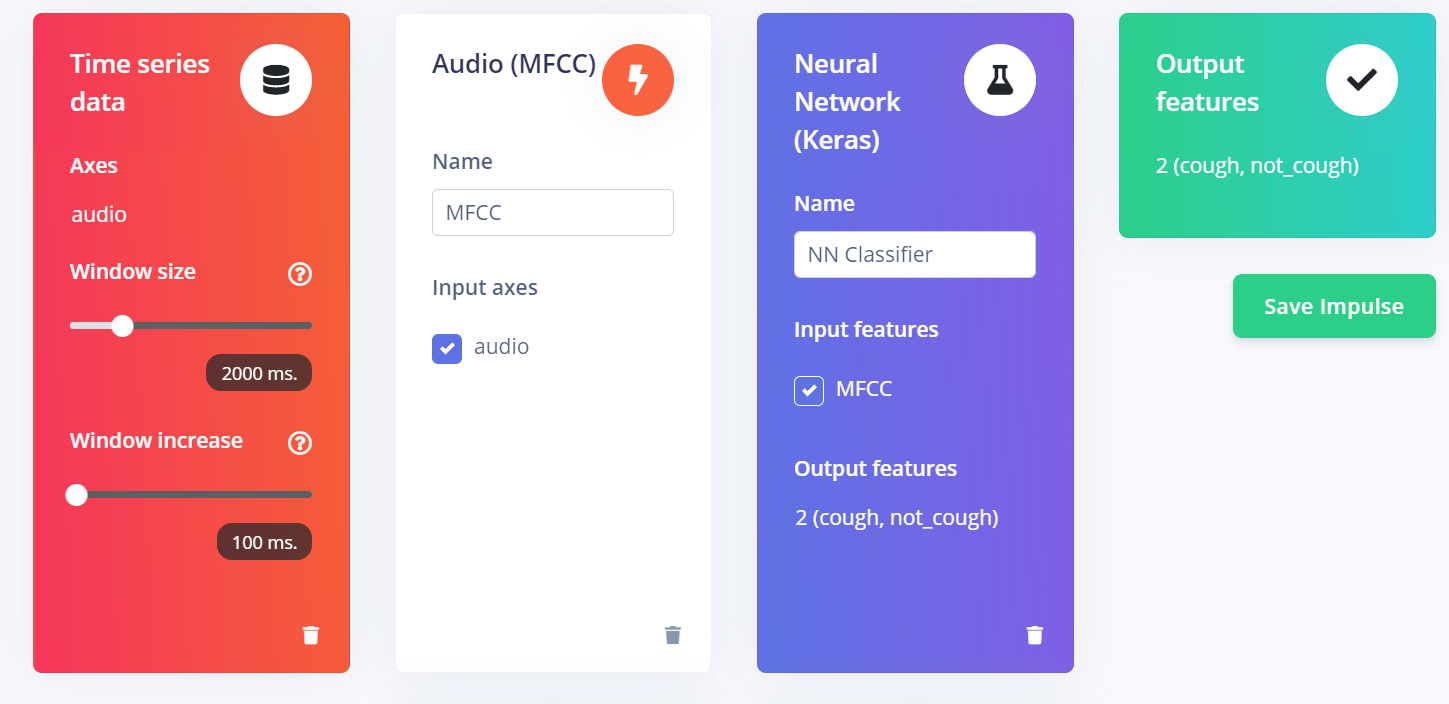
To build a model, we used the microphone array to collect multiple 5-second audio clips of coughs and not coughs and uploaded them to Edge Impulse. On Edge Impulse, we can choose the different methods to process and train the model. For audio classification, we used MFCC to process the data and neural network to train the model because it gave the optimal results. When we trained our model, we set the window size of the time series data to be 2 seconds and window increase of 0.1 seconds. This meant that the 5-second audio clip would be divided into 2-second segments with an increment of 0.1 seconds. Therefore, each clip would get classified 30 times, and it took the majority as the result. By doing this, the model would be more accurate. The figure below shows our training setup on Edge Impulse. Once we finished training the model, we then built a C++ library using Edge Impulse and deployed the model on the raspberry pi. To deploy the model, we followed a tutorial on Edge Impulse.
When we started testing our model locally, we needed to feed in the raw features of the audio clip to model. It took us quite a while to figure out how to process the audio clip and get the raw features that we saw on the Edge Impulse website. We made a post on Edge Impulse forum and someone answered our question. We were then able to write a python script that generated the raw features. Our microphone has four channels. The raw features were the average of the decimal PCM values from the WAV file across the four channels. So we wrote a script to read out the frames from the WAV file and average across the 4 channels to create a single raw features array. We only calculate raw features for the first two seconds because our window size was set to 2 seconds. We then stored the features array into a text file so that we could feed the text file into our feature to generate a result.
After we figured out how to get the raw features, we were able to write a python script that took an audio clip as input, processed it to get the raw features, fed the raw features into our model, and got a result. These figures below show the results that we were getting.
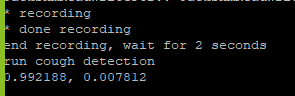
Model running while coughing into the microphone
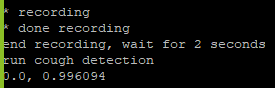
Model running while talking into the microphone
To now use our algorithm to detect coughs in real time, we wrote a script process_periods.py that records audio, runs it through the machine learning model, and keeps track of the number of coughs detected in a log file. First, it records 2 seconds of audio by calling our file “final_record.py” and saves the WAV file in the directory. Then, it calls the script wavetofloat.py to parse the WAV file into raw features, and saves that into a txt file. Then, it passes in the text file into our model, and parses the output to get the probability that there was a cough in the two seconds. Then, if the probability is over 0.9, we increment a count keeping track of the number of coughs, and go back to recording audio again. The total number of coughs is written to a log file total_cough.txt every pi (~3.14) seconds.
We ran into several inaccuracy problems when we tried using models trained on data collected in different environments than the testing environment. For example, we initially trained the model with the microphone sitting next to a window taped to a desk. Then when we moved the setup to be above the door frame, the accuracy plummeted. We also realized that using cough audio that was recorded on a different microphone than the one we embedded with our RPi led to inaccuracies when trying to classify data taken from the system’s microphone. Basically this meant that we needed to train the model in the exact environment that we plan on using the model. Because we changed setups frequently in order to make a good final demo video (working in Clara’s bedroom door frame is not an ideal environment), we were limited in how many samples we could take to train the model. Clara could cough for roughly 10 samples of 5s each before her chest started hurting. But she was able to take 30 samples of 5s each of just ambient talking in the room and 20 samples of 5s each of quiet. She trained the model using this limited set of data and was able to get a setup that mostly functioned for the final demo. But because the final demo had increased ambient noise due to kids starting to play outside and a zoom call going on that was not used for training the model, the accuracy was much lower than expected.
Originally, we planned to follow a tutorial on object detection and object tracking. The general idea is that periodically (once every so many frames) we’d check to see if any new objects have entered the frame and if any objects have been lost out of the frame. This detection would occur periodically because it is computationally taxing. When we are not trying to detect objects, we’d switch into the tracking mode where we’d create a tracker for each object to keep track of how it moves around in the camera frame. This tracking algorithm is computationally faster (as it should be) than detection.
However, the detection phase of the algorithm where it tries to find people in the frame took too long to process the frames in real-time. We achieved a rate of around 12 FPS, when we needed 30 FPS to run with a camera. We then tried to use multicore processing by introducing threading, but this only improved the FPS to 27 FPS. This resulted in camera feed that lagged and skipped, and people were not detected or tracked accurately.
We switched gears and wrote another script that used the NumPy and OpenCV Python libraries. This method proved to be much more successful, and we were then able to use our live camera feed to accurately track individuals entering and exiting a room.The picture below shows the PiCam tracking Clara’s hand as it passes through the screen, simulating a person walking through a door frame
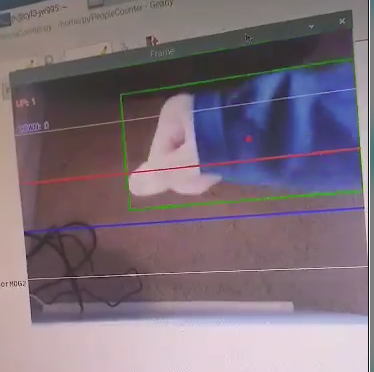
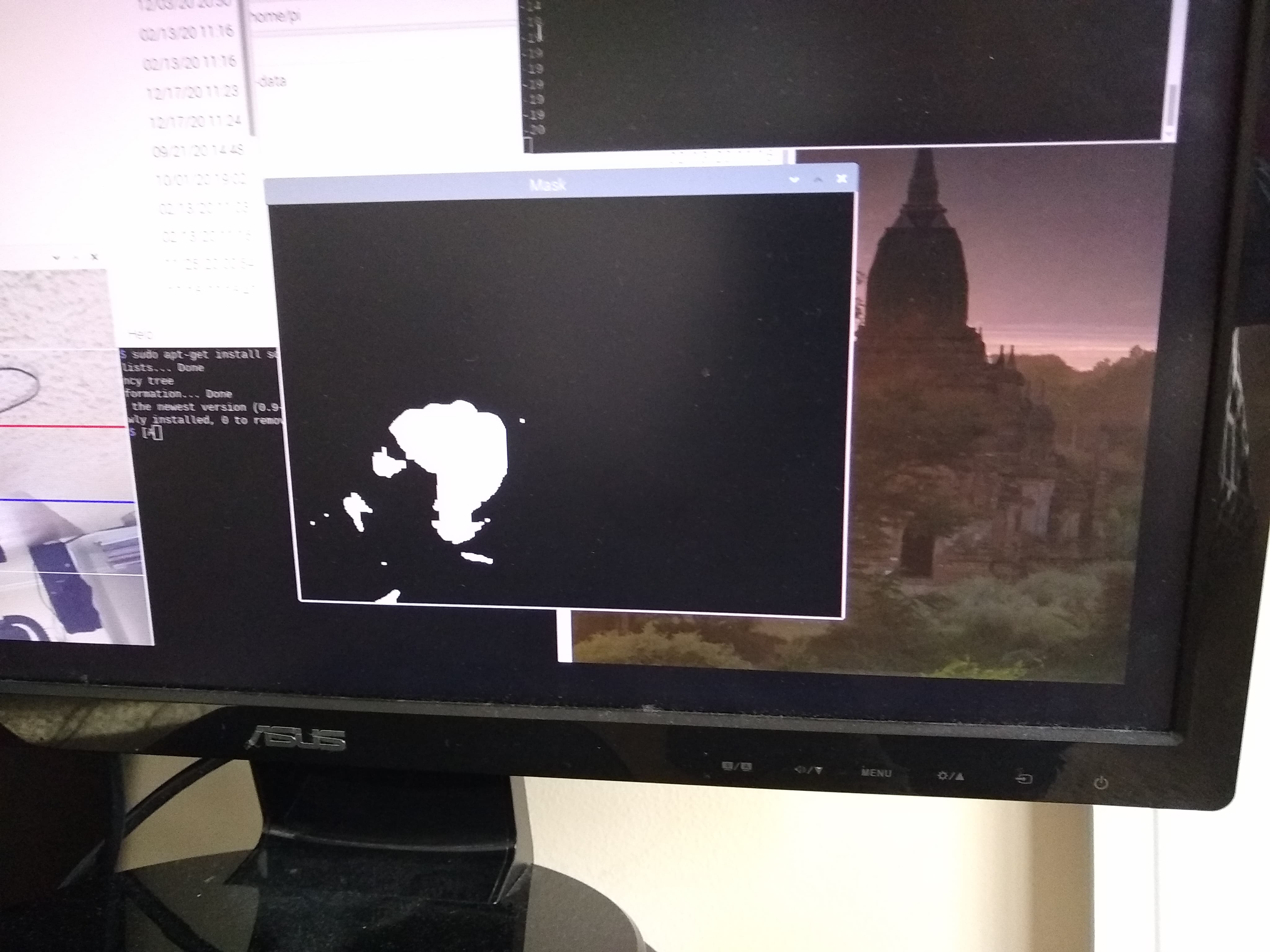
First, our algorithm uses the OpenCV background subtraction capability with detecting shadows enabled to eliminate the stationary, background elements of the camera frame. The figure belows the result of a person passing underneath the door after background subtraction.
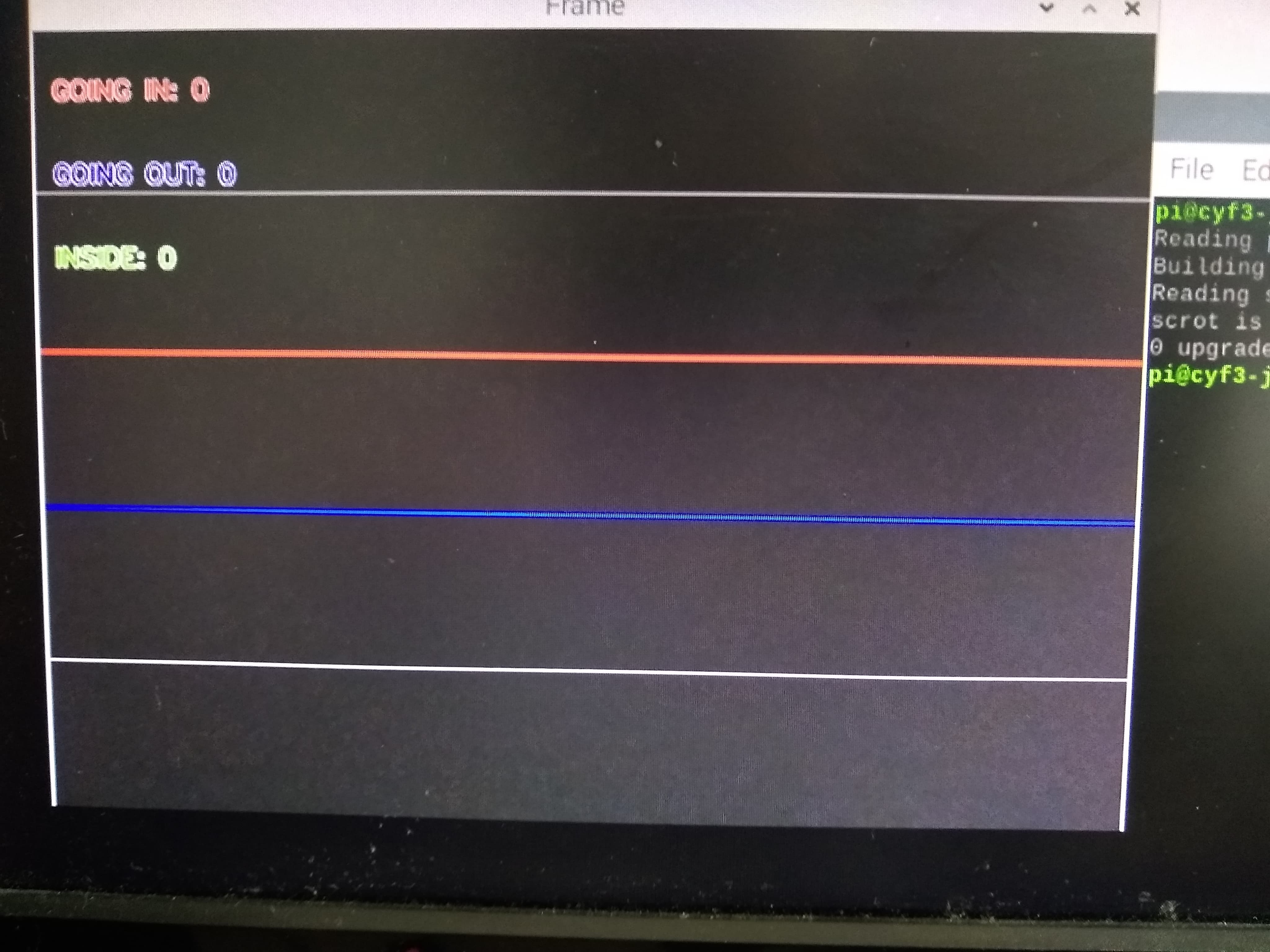
Then, people are counted by tracking contours as they pass through two lines, the red line and the blue line shown below. If the red line is passed first, then we know the person is moving down and exiting the room. If the blue line is passed first, then we know the person is moving up and entering the room.
By taking the difference between the number of people entering and exiting the room, we can know exactly how many people are in the room at a given time. We are able to make sure we aren’t counting new people with every contour detected by checking to see if a detected contour is within a small distance from a previously detected contour. If yes, then we assume this contour is already mapped to a person. We built a helper class called Person that kept track of a personal ID, the contour location, and the “age” of the person in frames. This script shows the camera feed with the blue and red lines, the number of people going in and out, and the number of people inside overlaid on top. It also shows the mask of the frame with the background subtracted out used for contour detection. Lastly, it writes to a txt file total_people.txt every pi seconds (~3.14 seconds) a single integer with the number of people in the room.
There are a few caveats with our people counter. Because we tried to use background subtraction and contour tracking, if someone were to sit in the door frame for an extended period of time and wave their arms around every now and then, our algorithm would subtract the person out due to them being stationary, then when they moved their arms around it would count that as being a new person and contours would be tracked. If the contours move over the blue and red lines, then people would be counted even though there is no one moving through the frame. This emphasizes that this system is designed for people walking through a door frame and not dilly dallying in the door frame. If they do, the algorithm will subtract them out of the frame when they’re stationary and count them as a new person when they start moving again.
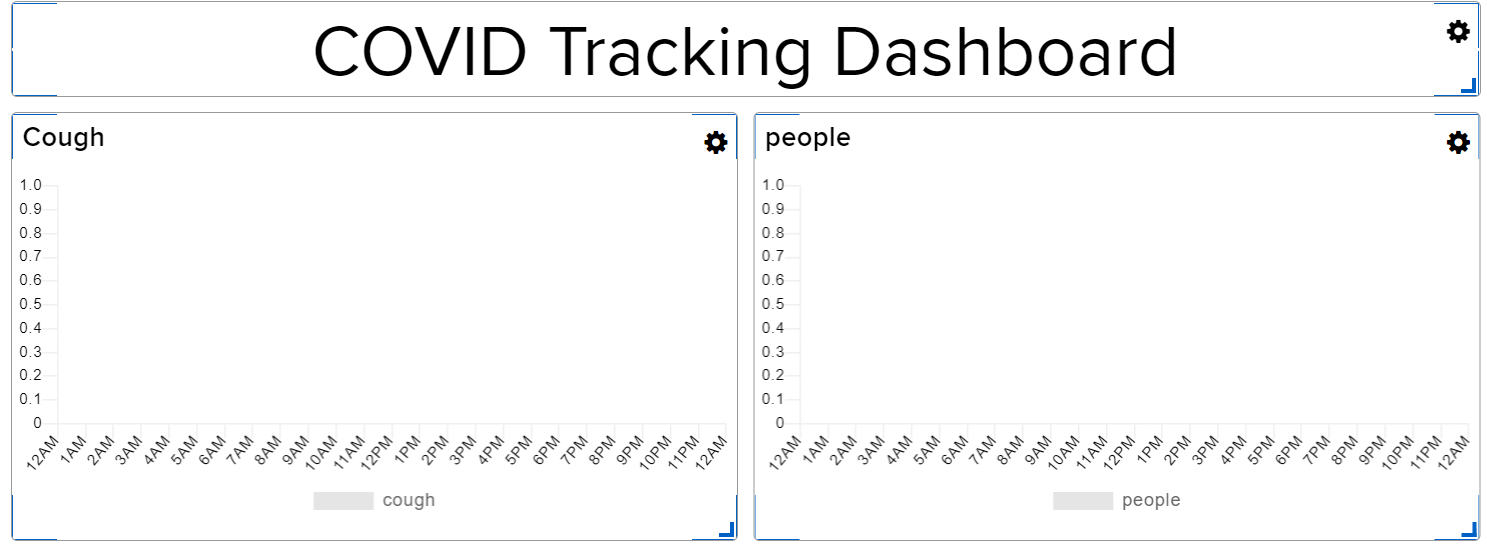
We decided that we would use Adafruit IO to implement our web GUI. Adafruit IO is a cloud service that the raspberry pi can connect to and send/retrieve data. To use the Adafruit IO, we needed to install the adafruit-io library. This is a very nice library that has many built-in functions that enables us to send live data to the web GUI. To set up the web GUI, we needed to create an adafruit account and made a new dashboard for our web GUI. We also needed to create two feeds, cough and people, to keep track of the number of coughs and number of people detected in the room. We associated the two feeds with line plots in the dashboard so that we could visualize our data. The figure below shows the layout of our dashboard.
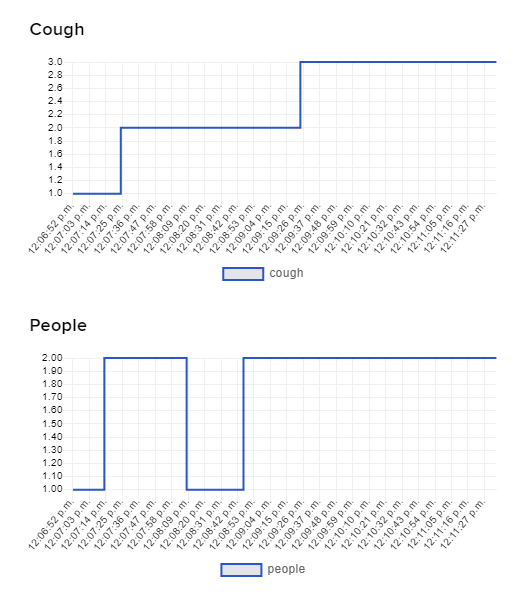
We update the web GUI with two log files. We have python scripts for detecting the number of people in the room and the number of coughs continuously and write those data in two separate text files. We updated the two text files every pi seconds, and we send the data to the web GUI every 5 seconds. This was because we wanted to avoid writing and reading the files at the same time, which could throw us an error. The figure below shows the web GUI getting data from the two log files and updating the cough and people data live. Note that because it only updates every 5 seconds, if a person walks in and out of a room within 5 seconds the count of the number of the people in the room will still be accurate, but the web GUI will not show the detailed change because it happened within such a short amount of time. In other words, the log files update immediately but they are only read every 10 seconds. The figure below shows an screenshot of the web GUI update.
To integrate the real-time web GUI, people counter, and cough detector, we wrote a simple bash script that starts the three different scripts: 1) live_feed.py, 2) PeopleCounter.py, and 3) process_periods.py. Each of them are run in the background.
Due to the constraint of working out of Clara’s bedroom with limited outlets and long cables, most of the testing was done with the setup on a desk with the camera hanging off the end pointing at the ground. We used a hand waving back and forth to test the people counter, and we just sat at a 5 foot distance from the microphone to record samples to train our neural network on.
For the final demo, we moved the whole set up to be on top of a door frame. Because the placement of the microphone was different, we had to take new coughing and not-coughing samples to retrain our model. We also mounted a light to hang off the edge of the door frame to maximize background subtraction and contour detecting and tracking accuracy.
In a real-world application, we wouldn’t need to have the long cables hanging down to connect to a monitor. We only kept the RPi connected to the monitor to ensure that the camera placement and lighting was ideal for people counting, and to start the program several times in a row since we didn’t use a piTFT. You can see the keyboard and mouse on the right side of the door frame.

The accuracy was very high for both the people counting and the cough detection. We only encountered a few errors when we waved our arms around when walking under the door frame or ran through the door frame, or when we yelled in a manner that mimicked a cough. The system could be improved by adjusting the minimum contour areas and tracking distances, and by taking many more samples of “not coughs” with music, cheering, laughing, etc. depending on the environment the system will be used in.
During the final demo, the cough accuracy was lower than usual. This is probably because the RPi had been running for a while and it started giving an overheating warning during the final demo zoom call. Additionally, there was a lot of extra noise that was not present when the model was being trained, so this probably confused our algorithm into classifying coughs as not coughs. This could have been solved by taking more data with the exact same environment as the final demo.
In a real world application of our project, we imagine our setup being trained over many weeks rather than in 20 min before the final demo. This means that it would experience a vast range of environments and ambient noises to pick up on more of the subtleties of detecting a cough. The training data would be much richer and the model would be much more accurate.
We discovered that building a model using only 10 cough samples and 50 not cough samples in a quiet bedroom with no one around and no one on Zoom is not enough to build a model that could generalize to any environment. We also discovered that contour tracking and background subtraction to track people relies on people continuously moving in and out of the door frame rather than standing in the door frame for extended periods of time.
In the future, we could train our model of the course of many days to collect much more training data with different kinds of environments and different levels and kinds of ambient noise. This would lead to a much higher cough detection accuracy. We could also investigate how to use a more computationally expensive approach to people tracking so that it uses actual people recognition rather than just contour recognition. This would solve the problem of stationary people in the frame that get subtracted out because they are considered by the algorithm to be part of the background.

Important Codes are shown below. For all the source code that we used to build the system, please refer to the github repository. :)
This script record a two second audion sample continuously.
import pyaudio
import wave
RESPEAKER_RATE = 8000
RESPEAKER_CHANNELS = 4
RESPEAKER_WIDTH = 2
# run getDeviceInfo.py to get index
RESPEAKER_INDEX = 2 # refer to input device id
CHUNK = 1024
RECORD_SECONDS = 2.5
WAVE_OUTPUT_FILENAME = "two-second-cough.wav"
p = pyaudio.PyAudio()
stream = p.open(
rate=RESPEAKER_RATE,
format=p.get_format_from_width(RESPEAKER_WIDTH),
channels=RESPEAKER_CHANNELS,
input=True,
input_device_index=RESPEAKER_INDEX,)
print("* recording")
frames = []
for i in range(0, int(RESPEAKER_RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(RESPEAKER_CHANNELS)
wf.setsampwidth(p.get_sample_size(p.get_format_from_width(RESPEAKER_WIDTH)))
wf.setframerate(RESPEAKER_RATE)
wf.writeframes(b''.join(frames))
wf.close()
This script takes a two-second audio sample, generate the raw features, and store the raw features in a text file.
import wave
import struct
import subprocess
import sys
import re
import ast
number_cough = 0
def parse_model_output():
output_file = open ("/home/pi/example-standalone-inferencing/cough_result.txt",'r')
a = output_file.readlines()
a = a[0].split('\\n')
a = a[-3]
cough_final = ast.literal_eval(a)
#y = re.split('\t|\n', cough)
#not_cough = a[4]
#z = re.split('\t|\n', not_cough)
#cough_prob = float(y[1])
#not_cough_prob = float(z[1])
return cough_final[0], cough_final[1]
def pcm_channels(wave_file):
"""Given a file-like object or file path representing a wave file,
decompose it into its constituent PCM data streams.
Input: A file like object or file path
Output: A list of lists of integers representing the PCM coded data stream channels
and the sample rate of the channels (mixed rate channels not supported)
"""
stream = wave.open(wave_file, "rb")
num_channels = stream.getnchannels()
sample_rate = stream.getframerate()
sample_width = stream.getsampwidth()
num_frames = stream.getnframes()
raw_data = stream.readframes(num_frames) # Returns byte data
stream.close()
total_samples = num_frames * num_channels
if sample_width == 1:
fmt = "%iB" % total_samples # read unsigned chars
elif sample_width == 2:
fmt = "%ih" % total_samples # read signed 2 byte shorts
else:
raise ValueError("Only supports 8 and 16 bit audio formats.")
integer_data = struct.unpack(fmt, raw_data)
del raw_data # Keep memory tidy (who knows how big it might be)
channels = [[] for time in range(num_channels)]
for index, value in enumerate(integer_data):
bucket = index % num_channels
channels[bucket].append(value)
return channels, sample_rate
channels, sample_rate = pcm_channels("/home/pi/example-standalone-inferencing/two-second-cough.wav")
new_data = []
num_channels = len(channels)
num_points = 16000
for i in range(num_points):
sum = 0
for k in range(num_channels):
sum += channels[k][i]
new_data.append(sum / num_channels)
#print(new_data)
myfile = open("/home/pi/example-standalone-inferencing/result.txt","w")
for x in range(0,len(new_data)):
if x != len(new_data)-1:
myfile.write(str(new_data[x]))
myfile.write(", ")
else:
myfile.write(str(new_data[x]))
myfile.close()
model_output = subprocess.check_output("./build/edge-impulse-standalone result.txt", shell=True)
original_stdout = sys.stdout
with open("/home/pi/example-standalone-inferencing/cough_result.txt","w") as f:
sys.stdout = f
print(model_output)
sys.stdout = original_stdout
cough_prob, not_cough_prob = parse_model_output()
print(str(cough_prob) + "," + str(not_cough_prob))
This script detects the number of people in the room and writes it to a text file.
import numpy as np
import cv2 as cv
import Person
import time
import math
#Variable to keep track of people crossing the entrance and exit lines.
cnt_up = 0
cnt_down = 0
#Create a log file to keep track of people entering and exiting the room.
try:
log = open('/home/pi/example-standalone-inferencing/total_people.txt',"w")
except:
print("Unable to create log file.")
log.write("" + str(cnt_up - cnt_down) + "\n")
log.flush()
log.close()
RED = (255, 0, 0)
GREEN = (0, 255, 0)
BLUE = (0, 0, 255)
WHITE = (255, 255, 255)
H = 480
W = 640
frameArea = H*W
areaTH = frameArea/250
print( 'Area Threshold', areaTH)
#Entering and exiting lines
line_up = int(H * (2 / 5))
line_down = int(H * (3 / 5))
up_limit = int(H * (1 / 5))
down_limit = int(H * (4 / 5))
print("Red line y:",str(line_down))
print("Blue line y:", str(line_up))
#Start the video stream.
cap = cv.VideoCapture(0)
# cap = cv.VideoCapture('/TestFiles/TestVideo.avi')
time.sleep(0.1)
# Background subtraction
backgroundSubtractor = cv.createBackgroundSubtractorMOG2(detectShadows = True)
kernelOp = np.ones((3,3),np.uint8)
kernelOp2 = np.ones((5,5),np.uint8)
kernelCl = np.ones((11,11),np.uint8)
#Variables
font = cv.FONT_HERSHEY_SIMPLEX
persons = []
max_p_age = 5
pid = 1
start_time = time.time()
while(cap.isOpened()):
if(time.time() - start_time > math.pi):
try:
log = open('/home/pi/example-standalone-inferencing/total_people.txt',"w")
except:
print("Unable to create log file.")
log.write("" + str(cnt_up - cnt_down) + "\n")
print(str(cnt_up - cnt_down))
log.flush()
log.close()
start_time = time.time()
ret, frame = cap.read()
for i in persons: # cycle through every person that's been detected so far
i.age_one() # age every person one frame
# ******* PRE-PROCESSING ******* #
#Apply background subtractor
fgmask = backgroundSubtractor.apply(frame)
fgmask2 = backgroundSubtractor.apply(frame)
#Binarization
try:
ret,imBin= cv.threshold(fgmask,200,255,cv.THRESH_BINARY)
mask = cv.morphologyEx(imBin, cv.MORPH_OPEN, kernelOp)
mask = cv.morphologyEx(mask , cv.MORPH_CLOSE, kernelCl)
except:
print('EOF')
print( 'UP:',cnt_up)
print ('DOWN:',cnt_down)
break
##### CONTOURS #####
# RETR_EXTERNAL returns only extreme outer flags. All child contours are left behind.
contours0, hierarchy = cv.findContours(mask,cv.RETR_EXTERNAL,cv.CHAIN_APPROX_SIMPLE)
for cnt in contours0:
area = cv.contourArea(cnt)
if area > areaTH:
##### TRACKING #####
M = cv.moments(cnt)
cx = int(M['m10']/M['m00'])
cy = int(M['m01']/M['m00'])
x,y,w,h = cv.boundingRect(cnt)
new = True
if cy in range(up_limit,down_limit):
for i in persons:
if abs(x-i.getX()) <= w and abs(y-i.getY()) <= h:
# this person was already detected previously
new = False
i.updateCoords(cx,cy) # updates coordinates and resets age
if i.going_UP(line_down,line_up) == True:
cnt_up += 1;
# print( "ID:",i.getId(),'crossed going up at',time.strftime("%c"))
# log.write("ID: "+str(i.getId())+' crossed going up at ' + time.strftime("%c") + '\n')
elif i.going_DOWN(line_down,line_up) == True:
cnt_down += 1;
# print( "ID:",i.getId(),'crossed going down at',time.strftime("%c"))
# log.write("ID: " + str(i.getId()) + ' crossed going down at ' + time.strftime("%c") + '\n')
break
if i.getState() == '1':
if i.getDir() == 'down' and i.getY() > down_limit:
i.setDone()
elif i.getDir() == 'up' and i.getY() < up_limit:
i.setDone()
if i.timedOut():
index = persons.index(i)
persons.pop(index)
del i # release memory
if new == True:
p = Person.MyPerson(pid,cx,cy, max_p_age)
persons.append(p)
pid += 1
cv.circle(frame,(cx,cy), 5, (0,0,255), -1)
img = cv.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
for i in persons:
cv.putText(frame, str(i.getId()),(i.getX(),i.getY()),font,0.3,i.getRGB(),1,cv.LINE_AA)
##### DRAWING #####
cv.line(frame, (0, 4 * H // 5), (W, 4 * H // 5), WHITE, 1)
cv.line(frame, (0, 3 * H // 5), (W, 3 * H // 5), RED, 2)
cv.line(frame, (0, 2 * H // 5), (W, 2 * H // 5), BLUE, 2)
cv.line(frame, (0, 1 * H // 5), (W, 1 * H // 5), WHITE, 1)
cv.putText(frame, 'GOING IN: '+ str(cnt_up),(10,40),font,0.5,WHITE,2,cv.LINE_AA)
cv.putText(frame, 'GOING IN: '+ str(cnt_up),(10,40),font,0.5,BLUE,1,cv.LINE_AA)
cv.putText(frame, 'GOING OUT: '+ str(cnt_down),(10,90),font,0.5,WHITE,2,cv.LINE_AA)
cv.putText(frame, 'GOING OUT: '+ str(cnt_down),(10,90),font,0.5,RED,1,cv.LINE_AA)
cv.putText(frame, 'INSIDE: '+ str(cnt_up - cnt_down),(10,140),font,0.5,WHITE,2,cv.LINE_AA)
cv.putText(frame, 'INSIDE: '+ str(cnt_up - cnt_down),(10,140),font,0.5,GREEN,1,cv.LINE_AA)
cv.imshow('Frame',frame)
cv.imshow('Mask',mask)
#Press ESC to quit
k = cv.waitKey(30) & 0xff
if k == 27:
break
log.flush()
log.close()
cap.release()
cv.destroyAllWindows()
This script creates two feeds, cough and people, and update them live on Adafruit IO by reading two log files.
import time
from Adafruit_IO import Client, Feed, RequestError
people = 0
cough = 0
ADAFRUIT_IO_KEY = 'aio_YSZl52xJYLt5VoLcrjWjfRViU9Ge'
ADAFRUIT_IO_USERNAME = 'ccchloew'
# Create an instance of the REST client.
aio = Client(ADAFRUIT_IO_USERNAME, ADAFRUIT_IO_KEY)
try: # for updating number of people
people_feed = aio.feeds('people')
cough_feed = aio.feeds('cough')
except RequestError: # create a people feed
feed = Feed(name="people")
people_feed = aio.create_feed(feed)
feed2 = Feed(name="cough")
cough_feed = aio.create_feed(feed2)
def read_people_file():
global people
myfile = open('total_people.txt','rt')
#read the entire file to string
temp = myfile.read().replace('\n', '')
print("temp " + temp)
people = int(temp)
print("my contents " + str(people))
myfile.close()
def read_cough_file():
global cough
myfile2 = open('total_coughs.txt','rt')
#read the entire file to string
temp = myfile2.read().replace('\n', '')
print("temp " + temp)
cough = int(temp)
print("my contents " + str(cough))
myfile2.close()
while True:
read_people_file()
aio.send(people_feed.key,str(people))
read_cough_file()
aio.send(cough_feed.key, str(cough))
time.sleep(10)
How to classify audio on Edge Impulse
How to deploy C++ model on Raspberry pi using Edge Impulse
How to setup Adafruit IO for live update
Total Cost: $29.90